Easy to use Fluentd, combined with Rainbond plugin market, log collection is faster
This article introduces the use of the Fluentd plugin in Rainbond to collect business logs and output to multiple different services.
There was an article in the past that introduced EFK (Kibana + ElasticSearch + Filebeat)plug-in log collection.The Filebeat plugin is used to forward and centralize log data and forward them to Elasticsearch or Logstash for indexing, but Filebeat, as a member of Elastic, can only be used across the entire Elastic stack.
Fluentd
Fluentd is an open source, distributed log collection system, which can collect logs from different services and data sources, filter and process the logs, and distribute them to various storage and processing systems.It supports various plug-ins and data caching mechanisms, and requires very few resources. It has built-in reliability, and combined with other services, it can form an efficient and intuitive log collection platform.
1. Integrated Architecture
When collecting component logs, you only need to enable the Fluentd plugin in the component. This article will demonstrate the following two methods:
- Kibana + ElasticSearch + Fluentd
- Minio + Fluentd
We made Fluentd as Rainbond's general type plug-in After the application is started, the plug-in also starts and automatically collects logs and outputs to multiple service sources. The whole process is non-intrusive to the application container and has strong scalability.
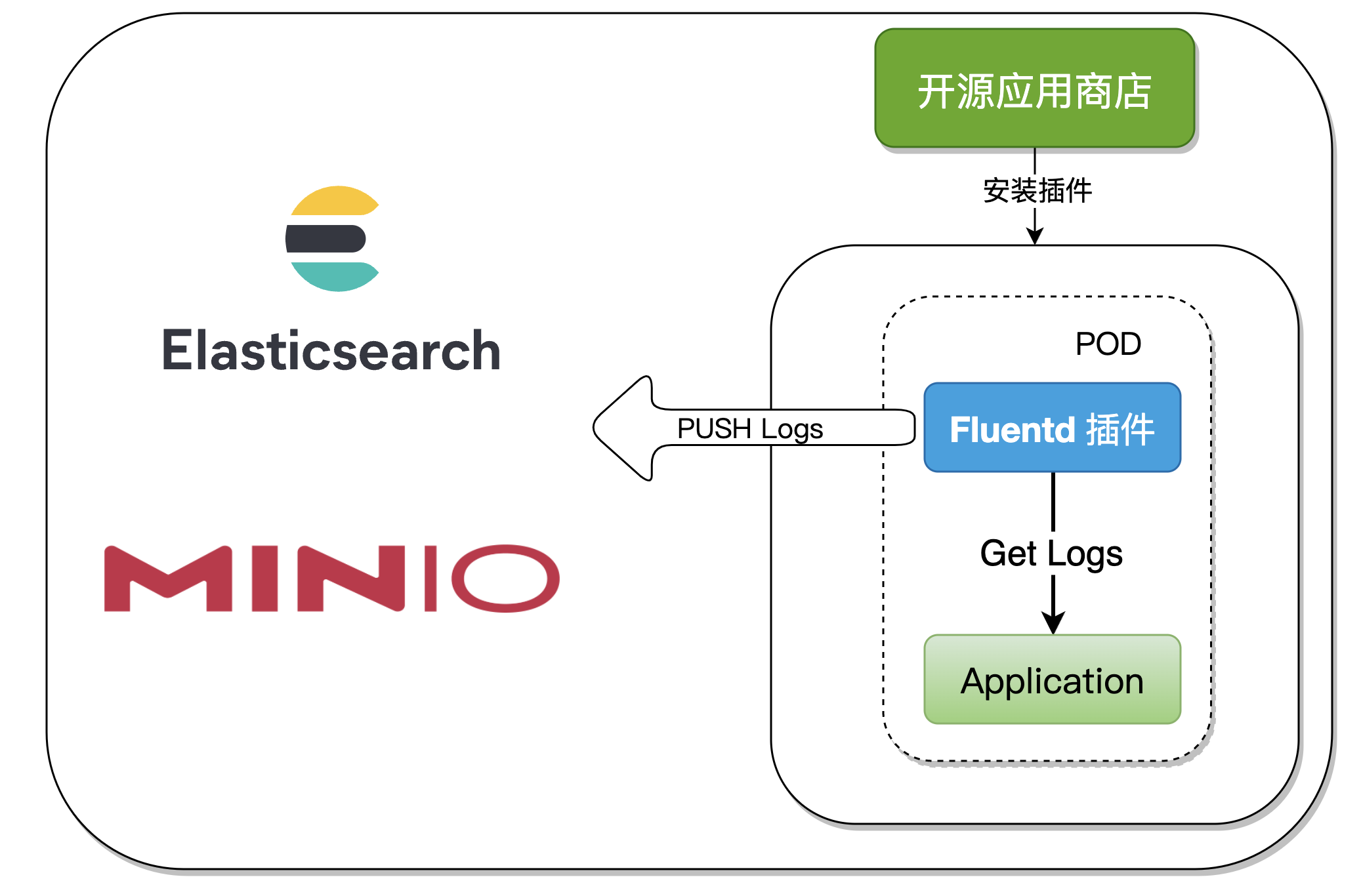
Second, the plug-in principle analysis
Rainbond V5.7.0 has added:Install plugins from open source app storesThe plugins in this article have been released to open source app stores. When we use them, we can install them with one click, and modify the configuration files as needed.
The Rainbond plug-in system is a part of the Rainbond application model. The plug-ins are mainly used to realize the extended operation and maintenance capabilities of the application container.Because the implementation of operation and maintenance tools has a large commonality, the plug-in itself can be reused.Plugins have runtime status only when they are bound to the application container to implement an operation and maintenance capability, such as performance analysis plugins, network governance plugins, and initialization type plugins.
In the process of making Fluentd plug-ins, general type plug-insare used, which can be understood as one POD starts two Containers. Kubernetes natively supports starting multiple Containers in one POD, but the configuration is relatively complicated. User operation is simpler.
3. EFK log collection practice
The Fluentd-ElasticSearch7 output plugin writes log records to Elasticsearch.By default, it creates records using the bulk API, which performs multiple indexing operations in a single API call.This reduces overhead and can greatly improve indexing speed.
3.1 Operation steps
Both applications (Kibana + ElasticSearch) and plugins (Fluentd) can be deployed with one click through open source app stores.
- Docking with open source app stores
- Search
elasticsearchin app store and install7.15.2version. - Team View -> plugins -> install from app store
Fluentd-ElasticSearch7plugins - Create a component based on an image, the image uses
nginx:latest, and the mount storage isvar/log/nginx.Here useNginx:latestas demo- After the storage is mounted in the component, the plugin will also mount the storage and access the log files generated by Nginx.
- Open the plug-in in the Nginx component, you can modify the
Fluentdconfiguration file as needed, please refer to the introduction to the configuration file below.
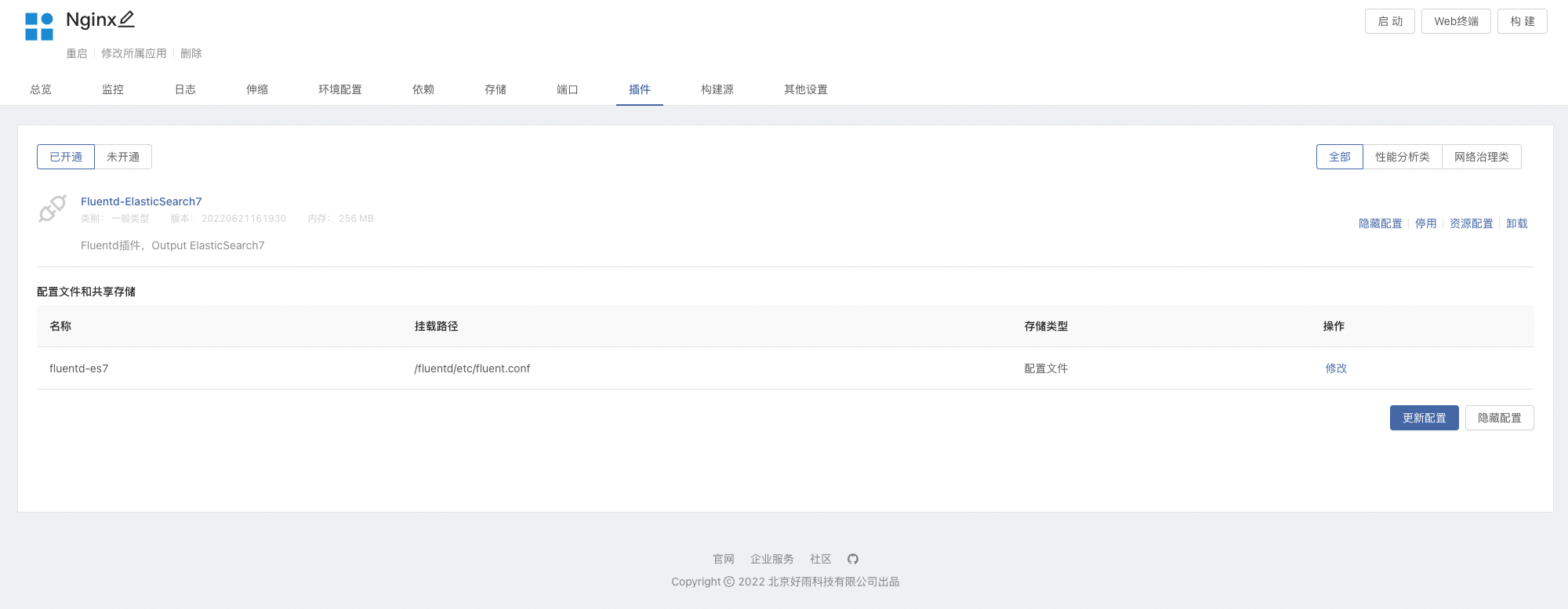
- Add ElasticSearch dependencies and connect Nginx to ElasticSearch, as shown in Figure:below
-
Visit
Kibanapanel, go to Stack Management -> Data -> Index Management, you can see that the existing index name isfluentd.es.nginx.log, -
Access the
Kibanapanel, go to Stack Management -> Kibana -> Index Mode, and create an index mode. -
Go to Discover, and the log is displayed normally.
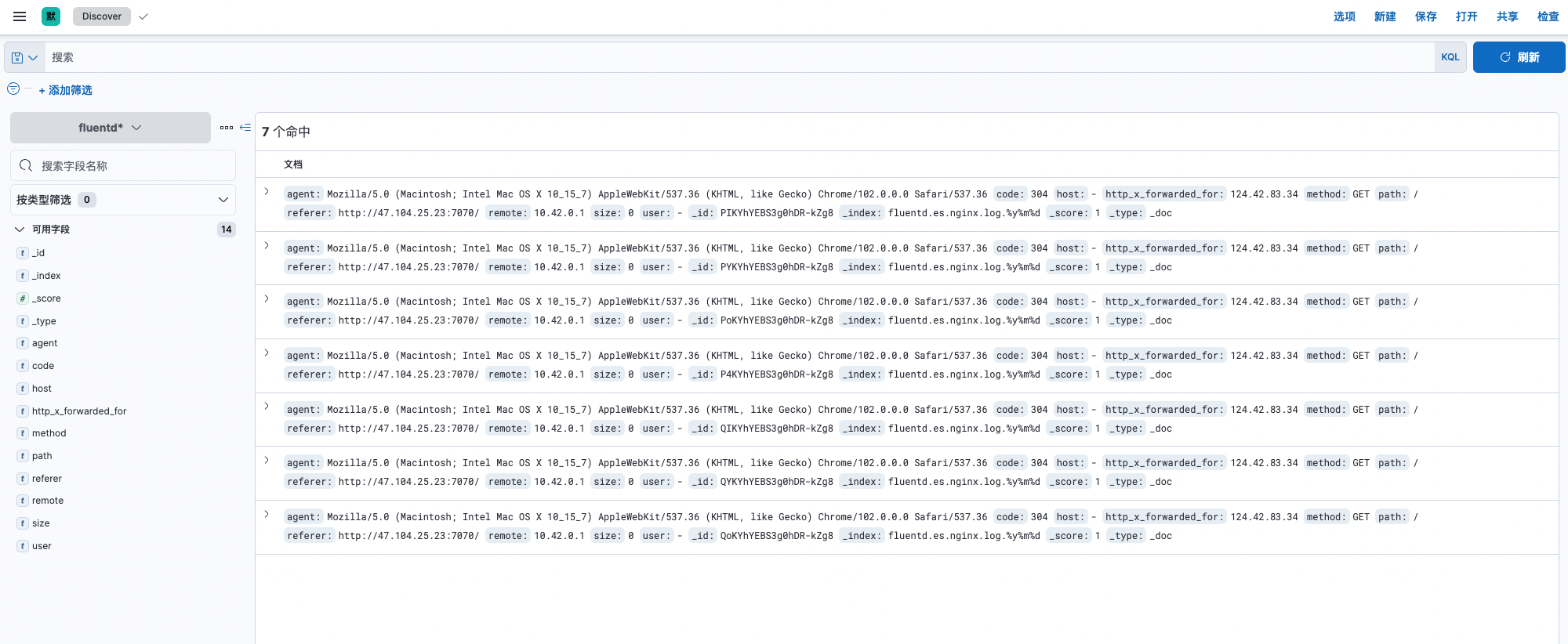
3.2 Introduction to configuration files
Configuration file reference Fluentd documentation output_elasticsearch.
<source>
@type tail
path /var/log/nginx/access.log,/var/log/nginx/error.log
pos_file /var/log/nginx/nginx.access.log.pos
<parse>
@type nginx
</parse>
tag es.nginx.log
</source>
<match es.nginx.**>
@type elasticsearch
log_level info
hosts 127.0.0.1
port 9200
user elastic
password elastic
index_name fluentd.${tag}
<buffer>
chunk_limit_size 2M
queue_limit_length 32
flush_interval 5s
retry_max_times 30
</buffer>
</match>
Configuration item explanation:
| configuration item | explain |
|---|---|
| @type | Collection log type, tail indicates incremental read log content |
| path | Log path, multiple paths can be separated by commas |
| pos_file | Used to mark the path where the position file has been read |
| \parse \parse | For log format parsing, write the corresponding parsing rules according to your own log format. |
| configuration item | explain |
|---|---|
| @type | Type of service output to |
| log_level | Set the output log level to info; the supported log levels are:fatal, error, warn, info, debug, trace. |
| hosts hosts | address of elasticsearch |
| port | port of elasticsearch |
| user/password | Username/password used by elasticsearch |
| index_name | index defined name |
| \buffer\buffer | The log buffer is used to cache log events and improve system performance.Memory is used by default, and file files can also be used |
| chunk_limit_size | Maximum size of each block: events will be written in blocks until the size of the block becomes this size, the memory defaults to 8M, and the file is 256M |
| queue_limit_length | The queue length limit for this buffer plugin instance |
| flush_interval | Buffer log flush event, the default is to flush the output once every 60s |
| retry_max_times | Maximum number of times to retry failed block output |
The above are only some of the configuration parameters, other configurations can be customized with the official website documentation.
Fourth, Fluentd + Minio log collection practice
The Fluentd S3 output plugin writes log records to standard S3 object storage services such as Amazon, Minio.
4.1 Operation steps
Both applications (Minio) and plugins (Fluentd S3) can be deployed with one click through the open source app store.
-
Docking with open source app stores.Search for
minioin the open source app store, and install22.06.17version. -
Team View -> Plugins -> Install
Fluentd-S3Plugins from the app store. -
Access the Minio 9090 port, the user password is obtained in the Minio component-> dependency.
-
Create Bucket with custom name.
-
Go to Configurations -> Region and set Service Location
- In the configuration file of the Fluentd plugin,
s3_regiondefaults toen-west-test2.
- In the configuration file of the Fluentd plugin,
-
-
Create a component based on an image, the image uses
nginx:latest, and the mount storage isvar/log/nginx.Here useNginx:latestas demo- After the storage is mounted in the component, the plugin will also mount the storage and access the log files generated by Nginx.
-
Enter the Nginx component, activate the Fluentd S3 plugin, and modify
s3_buckets3_regionin the configuration file
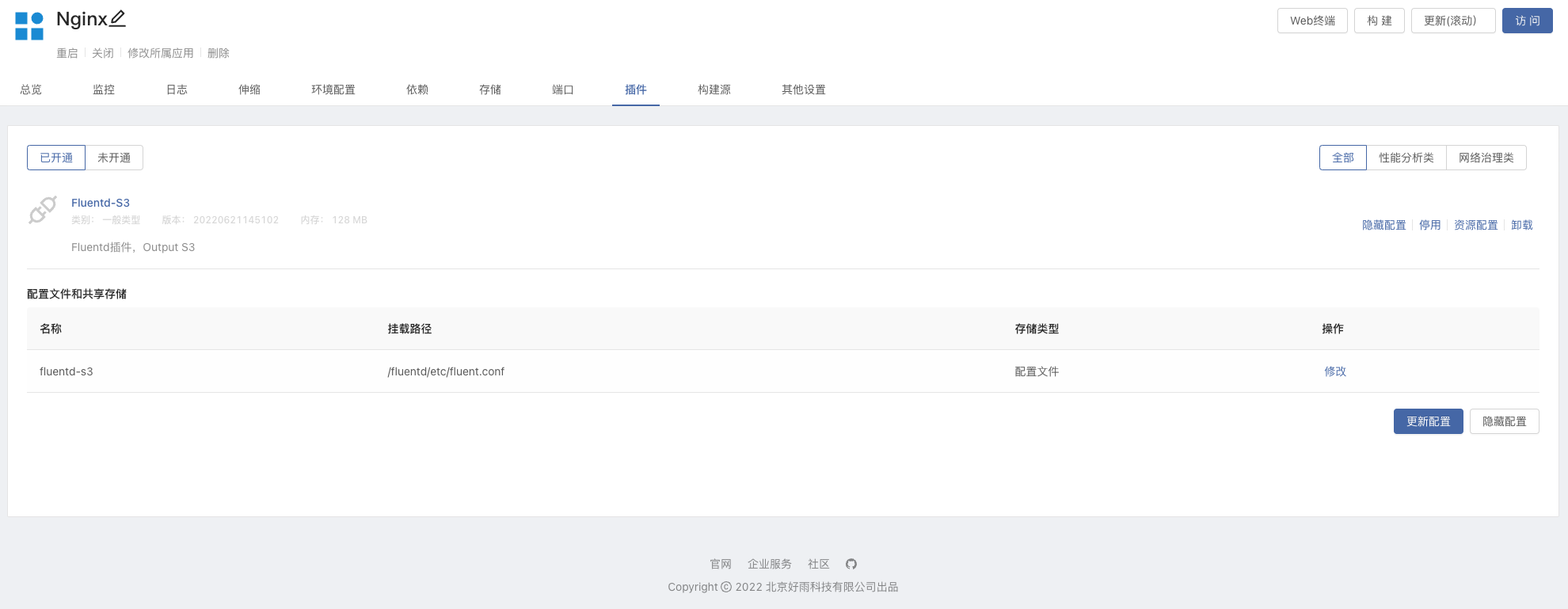
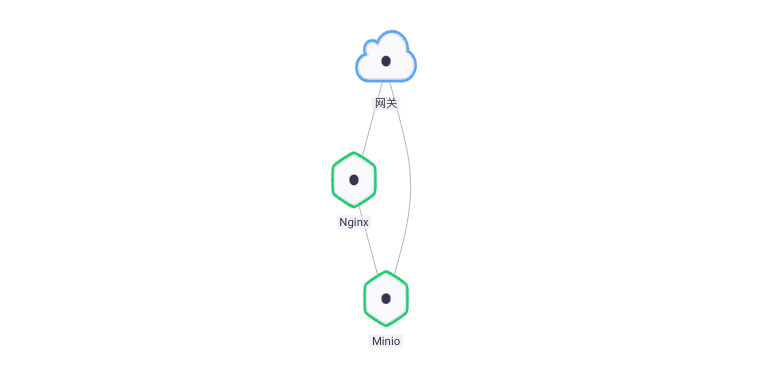
- Establish dependencies, Nginx components depend on Minio, and update the components to make them take effect.
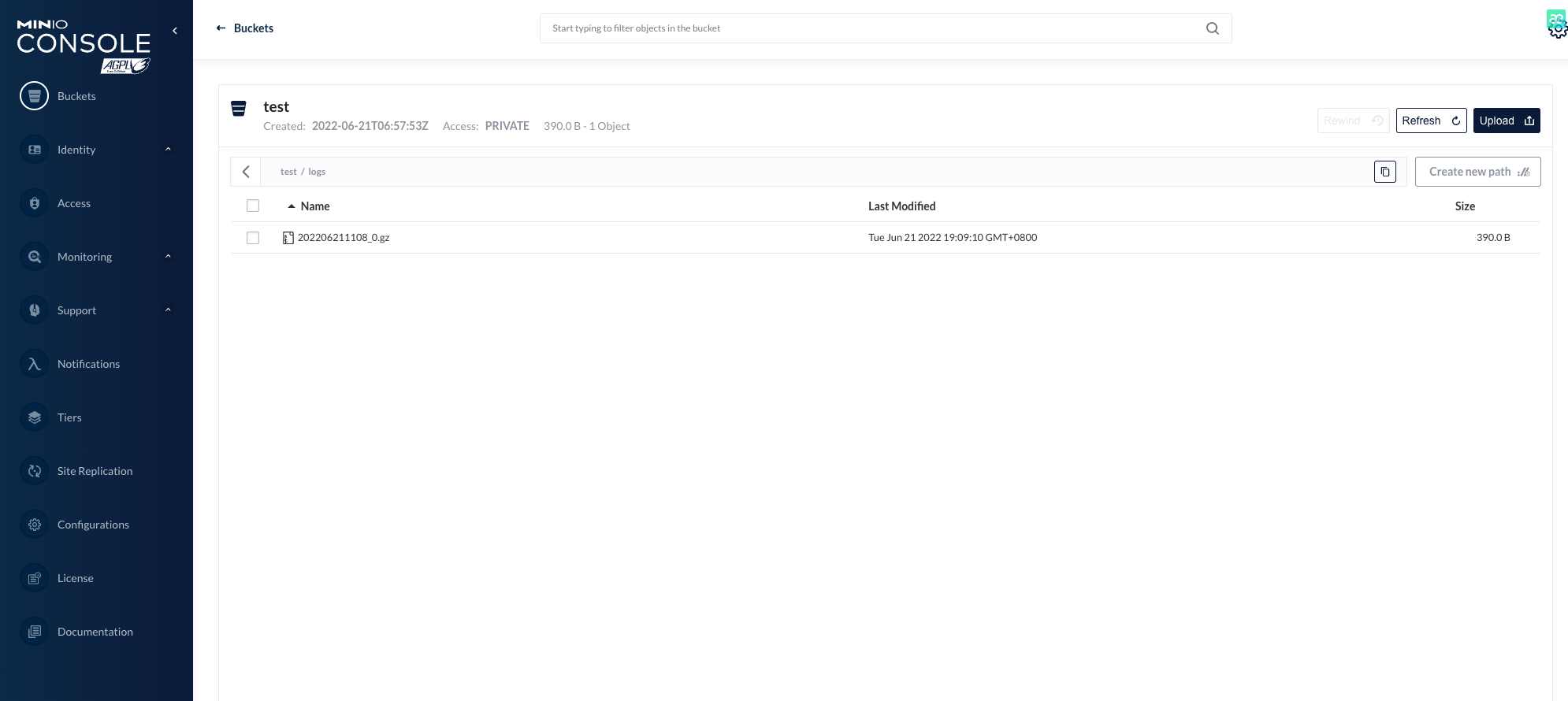
- Access the Nginx service and let it generate logs, which can be seen in Minio's Bucket in a few moments.
4.2 Introduction to configuration files
The configuration file refers to Fluentd document Apache to Minio.
<source>
@type tail
path /var/log/nginx/access.log
pos_file /var/log/nginx/nginx.access.log.pos
tag minio.nginx.access
<parse>
@type nginx
</parse>
</source>
<match minio.nginx.**>
@type s3
aws_key_id "#{ENV['MINIO_ROOT_USER']}"
aws_sec_key "#{ENV['MINIO_ROOT_PASSWORD']}"
s3_endpoint http://127.0.0.1:9000/
s3_bucket test
s3_region en -west-test2
time_slice_format %Y%m%d%H%M
force_path_style true
path logs/
<buffer time>
@type file
path /var/log/nginx/s3
timekey 1m
timekey_wait 10s
chunk_limit_size 256m
</buffer>
</match>
Configuration item explanation:
| configuration item | explain |
|---|---|
| @type | Collection log type, tail indicates incremental read log content |
| path | Log path, multiple paths can be separated by commas |
| pos_file | Used to mark the path where the position file has been read |
| \parse\parse | For log format parsing, write the corresponding parsing rules according to your own log format. |
| configuration item | explain |
|---|---|
| @type | Type of service output to |
| aws_key_id | Minio Username |
| aws_sec_key | Minio password |
| s3_endpoint | Minio access address |
| s3_bucket | Minio bucket name |
| force_path_style | Prevent AWS SDK from breaking endpoint URLs |
| time_slice_format | Add this timestamp to every filename |
| \buffer\buffer | The log buffer is used to cache log events and improve system performance.Memory is used by default, and file files can also be used |
| timekey | Accumulated chunks are refreshed every 60 seconds |
| timekey_wait | Wait 10 seconds to refresh |
| chunk_limit_size | Maximum size of each block |
at last
The Fluentd plugin can flexibly collect business logs and output to multiple services, and combined with the one-click installation of the Rainbond plugin market, it makes our use easier and faster.
At present, there are only Flunetd-S3 Flunetd-ElasticSearch7in the Rainbond open source plug-in application market, and you are welcome to contribute plug-ins!