云原生时代的DevOps平台设计之道
开发人员与运维人员是 IT 领域很重要的两大人群,他们都会参与到各种业务系统的建设过程中去。DevOps 是近年间火爆起来的一种新理念,这种理念被很多人错误的解读为“由开发人员(Dev)学习一大堆新的技能,从而掌握运维人员(Ops)该处理的事情”。然而能力越大,责任越大,当维持生产环境稳定为要位的运维责任落到开发人员的肩头时,多数程序员发出了 扯淡的DevOps,我们��开发者根本不想做运维! 的呼喊。那么在云原生时代,到底应该怎样达成 DevOps 的体验呢?我的观点是由平台工程来衔接这两大人群,各自做好各自领域的事情。
令人“厌恶”的DevOps
首先,我非常希望你能先看一看引言中提到的 扯淡的DevOps,我们开发者根本不想做运维! 这篇文章。这篇文章从亚马逊云科技社区参与负责人 Emily Freeman 的一条推特入手,观察了很多留言后,得出了文章标题这种类似咆哮一般的结论。从绝大多数回复这条推特的 IT 从业者的口中,我听到了对于将运维职责强加给开发人员这种 DevOps 体验深恶痛绝。
开发人员对于 “谁构建,谁运行” 这种大义凛然的话表示无感,对于学习运维领域的新技能,亦或是将自己加入轮班支持人员的行列都感觉力不从心;运维人员的本职工作被剥离之后,则对本专业的前景惶惶不安,会害怕运维团队的重新洗牌。
开发与运维,的的确确是两个不同的工种,有着类似“车床工与管道工”的区别。
| 开发人员 | 运维人员 | |
|---|---|---|
| 专业技能 | 开发语言、开发框架、中间件、数据库 | 硬件、操作系统、网络、存储、虚拟化 |
| 日常工作 | 理解需求、开发文档写作��、开发代码 | 安装部署、监控、日志、问题排查、变更 |
| 文化标签 | 自由、创造 | 保守、责任 |
一些公司认为从表格中把大量的运维人员管辖的工作,一股脑的“左移”给开发人员就是 DevOps。在专业技能和日常工作领域带来的缺口,可以通过开发人员的勤劳学习加以补足,然而在文化标签领域的冲突,将会是导致开发人员厌恶这种 DevOps 体验的根本原因。
DevOps 的真意与平台工程
在我看来,DevOps 的真意是利用软件工程思维,解决复杂且繁重的运维问题。真正适合做 DevOps 工作的人,是具备一定软件工程能力的运维专家,在这里,对运维能力的要求更重要。
DevOps 工程师,可以通过设计或选择一款平台产品,来将复杂的运维工作抽象为产品化的运维特征。从这个角度上讲,开发人员将会是这个平台产品的用户,他们能够在不了解复杂基础设施的情况下,操作并维护应用程序。DevOps 工程师,应该是更懂开发人员需求的运维工程师。
在追根溯源,找到了这条推特之后,我了解到了更多 IT 业内人士对 DevOps 的看法,从中找到了很多和我有共鸣的声音。
To me that's a sign we haven't made ops intuitive/easy enough for most devs to be able to handle it.
对我来说,这表明我们还没有让运维变得足够直观/简单,以至于大多数开发人员都无法处理它。
—— @Liz Fong-Jones (方禮真)
The "platform" should do the heavy lifting ops, lacking a real platform the ops team (DevOps/are/platform team) is the platform. Devs can then focus on the application level operations of their apps using the knobs and levers provided by the platform.
“平台”应该做繁重的运维,缺乏真正的平台时运维团队就是平台(DevOps/are/platform team)。然后,开发人员可以使用平台提供的旋钮和杠杆专注于其应用程序的应用程序级操作。
—— @pczarkowski
IT 行业近年来的发展趋势,一直是不断以平台能力的提升,来解决复杂基础设施的使用问题的。最开始,程序开发人员需要面对的是一台物理服务器,在缺乏运维能力的情况下,会由运维人员处理有关服务器的一切,包括操作系统、网络配置等等。而到现在,程序开发人员已经很少需要跟服务器打交道,甚至我见过的很多程序员并不掌握任何有关命令行的知识,就可以面向服务器开发应用系统。这种转变让程序开发人员更加专注于业务代码本身,不必分神去做一些繁重且琐碎的运维事务。带来这种转变的,是处于发展过程中的平台工程,在让基础设施不断变得简单易用。
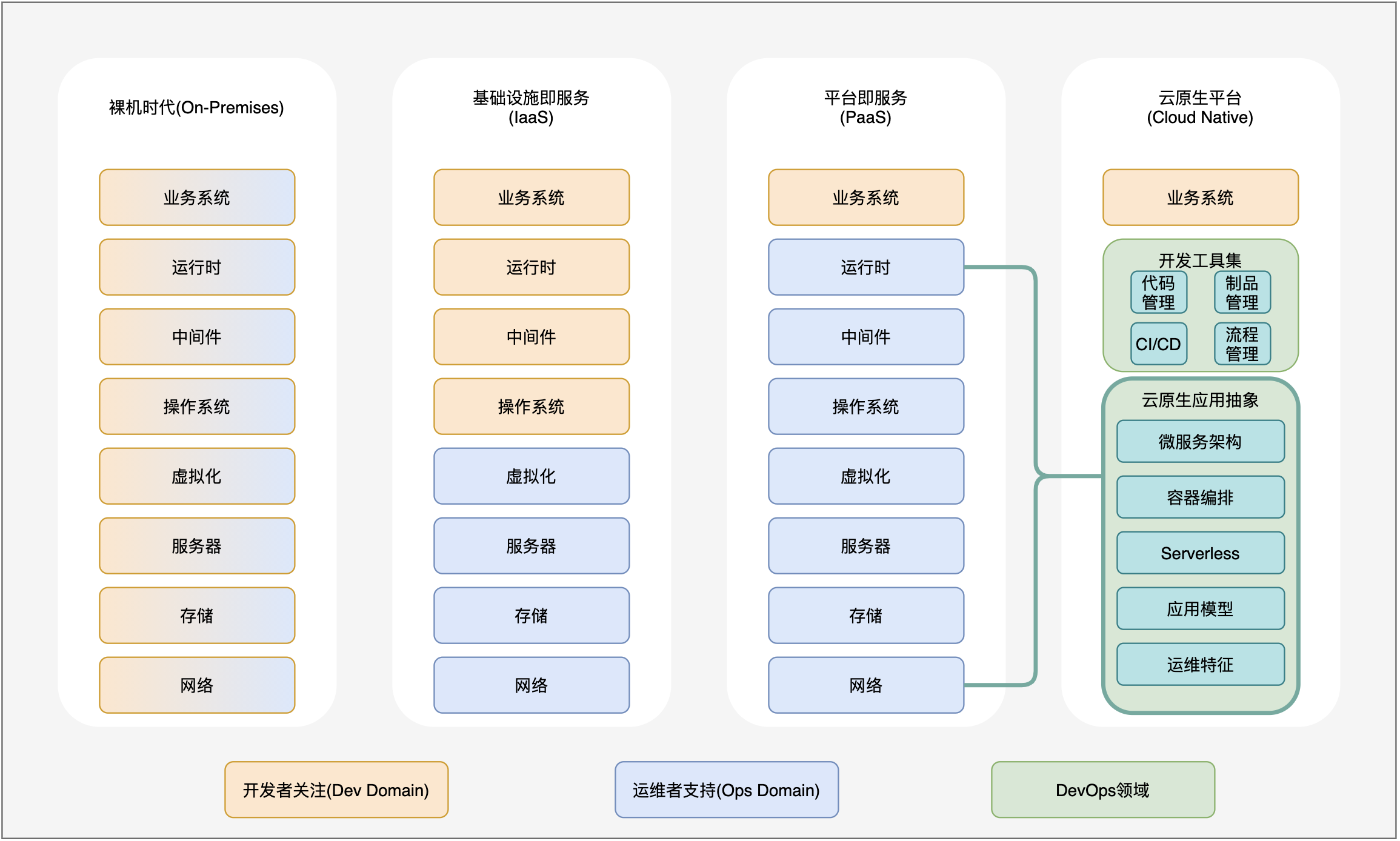
最原始的裸机时代,并没有开发运维之分。从底层基础设施,一直到最顶层的业务系统都是同一批人在处理,这一批老程序员可以被称为真正的全栈工程师。但毫无疑问,每一个开发人员,都希望能够抛却运维工作,更专注于自己开发的代码。
云计算时代的兴起以虚拟化技术为基础,软件定义基础设施变得炙手可热起来。运维人员��通过建设并维护一套 IaaS 云平台,将计算资源进行池化。开发人员按需申请自己需要的虚拟机,从而得到一个操作系统界面来进行交互。与操作系统打交道,对开发人员依然是个巨大的挑战,在 IT 领域,操作系统就像一座漂浮在海上的冰山,看似只露出冰山一角,然而其庞大的知识领域“身躯”都隐藏在海平面以下。和裸机时代相比较,开发人员和运维人员已经是两个完全不同的群体,开发人员已经可以将自己的大部分精力放在业务系统上了。值得一提的是,对操作系统的掌控是不折不扣的运维领域技能。
容器技术以及 Kuberentes 的横空出世,成为了云计算时代的分水岭。软件定义基础设施的技术手段已经被发挥到了极致,并且成为了现阶段运维人员的标配技能。运维人员通过建设并维护一套 PaaS 云平台,终于将操作系统这一座最后的“大山”从开发人员的身上搬开。开发人员可以将更多的精力放在业务系统上了,除了他们依然需要学习容器技术和 Kubernetes ,至少他们要学会如何面向 Kubernetes 编写业务系统所需的声明式配置文件。运维人员也通过 PaaS 云平台得到了自己想要的能力,容器技术和 Kubernetes 为他们带来了弹性、便捷性的巨大提升。
跟随时代的变迁,我得出了一个结论:从开发人员与运维人员的关系上来看,IT 领域的演变,就是运维人员通过不断向上接手开发人员眼中“跟开发无关的杂活”,来不断为开发人员减负。开发人员在得到了解放后,可以将视角更多的聚焦在自己开发的业务系统上,释放出自己的创造力。
那么跟随结论中的趋势,解放开发人员负担的脚步绝对不会停止。DevOps 的工作,就是以开发人员为用户群体,打造一套可以让开发人员毫无障碍的使用基础设施的“云原生平�台“。
云原生是一种面向云设计应用的思想理念,充分发挥云效能,组织内 IT 人员相互协作构建弹性可靠、松耦合、易管理、可观测的云应用系统,最终目标是提升软件交付效率,降低运维复杂度。相比上文中提到的 PaaS 平台,起码要能够避免开发人员去编写复杂的 Kubernetes 声明式配置文件。
现有开源产品情况
在云原生平台领域,已经有不少项目在深耕。在这里我列举了三个各具特色的云原生领域的平台级产品:Rancher、KubeSphere、Rainbond ,后续的具体设计思路中,也会关注已有产品的实现。
这三款开源产品中,Rancher 是元祖级容器管理平台,加入 SUSE 后,能够明显感觉在云原生生态领域不断发力,Rancher 在各个层次可以集成的云原生领域工具集已经非常丰富。Rancher 专注于帮助 DevOps 团队面对多集群情况下的运维和安全挑战,从这一点来说,Rancher 更偏向于运维人员的使用体验,而非面向开发人员提供更高的易用性。
KubeSphere 是来自青云的 “面向云原生应用的 容器混合云”。除了对 Kubernetes 集群内的各种资源的管理能力之外,Kubesphere 主打即插即用的插件式生态扩展能力。
Rainbond 由北京好雨科技出品,从其介绍来看,它是一款主打易用性的云原生多云管理平台。
降低业��务部署难度
诚实地讲,为现代开发语言开发而来的业务系统制作容器镜像并不是什么难以掌握的技能。但是不可否认的是,绝大多数 IT 从业人员依然会将制作镜像这件事情归为运维人员管理,而不是开发人员要关心的事情。
那么 DevOps 工程师就有必要考虑,如何在开发人员对容器技术一无所知的情况下,使之可以直接从代码开始部署业务系统。
在这个方面,Heroku 是无可争议的先行者。Heroku 是一个支持多种编程语言的云平台即服务产品。在2010年被 Salesforce.com 收购。 Heroku 作为最元祖的云平台之一,从2007年6月起开发,当时它仅支持 Ruby,但后来增加了对 Java、Node.js、Scala、Clojure、Python 以及 PHP 和 Perl 的支持。
开发人员在使用云原生平台时,只需要在界面中填写代码仓库的地址,对应的用户名密码等基础信息,就可以等待代码构建成为镜像,并自由的运行在 Kubernetes 云环境中去。
现有开源产品也在这方面给予了一定的支持:
| Rancher | KubeSphere | Rainbond | |
|---|---|---|---|
| 实现方式 | 通过集成 Epinio 项目,继而深入集成了Paketo Buildpacks 来实现源码构建 | 提供定制化的基础镜像来结合用户代码构建项目 | 基于 Heroku buildpack 定制的源码构建能力 |
| 支持语言类型 | Java、GraalVM、Golang、.NetCore、Nodejs、PHP、Ruby、Python | Java、Nodejs、Python | Java、Golang、.NetCore、Nodejs、PHP、Python、Html静态 |
| 使用体验 | 全部命令行操作,使用复杂 | 图形化操作,直接提供代码地址,构建产出镜像,进而部署业务 | 图形化操作,提供代码地址即可完成构建与部署,构建参数可配置,自由度高 |
更进一步的设计,是将代码的提交、检测、部署等流程都集成到 CI/CD 流水线中去,开发人员只需要进行代码的提交,后续的流程会自动触发完成,生成检测报告,并完成代码的上线部署。而与之相关的第三方工具集,由 DevOps 团队负责进行维护,开发人员可以充分的发扬拿来主义——拿来用就好。
在这方面 KubeSphere 做的更加全面,通过集成 Jenkins 实现了基于图形化的流水线配置,这种方式对于以前就在使用 Jenkins 的团队很友好。并且这种实现继承了 Jenkins 生态原有的高自由度,可以更好的将其他第三方CI工具纳入流程之中。
Rainbond 通过在构建流程中加入自制的自动触发能力,也可以完成部分流水线工作。这种配置相对编写 Jenkinsfile 来说更简单一些,能够满足一些基本场景。然而其扩展性和自由度不足,能够接纳的第三方CI工具不够丰富。
Rancher 并没有在产品中集成 CI 方面的能力,在 CD 方面通过集成 fleet 项目来实现 GitOps ,使用的门槛较高。
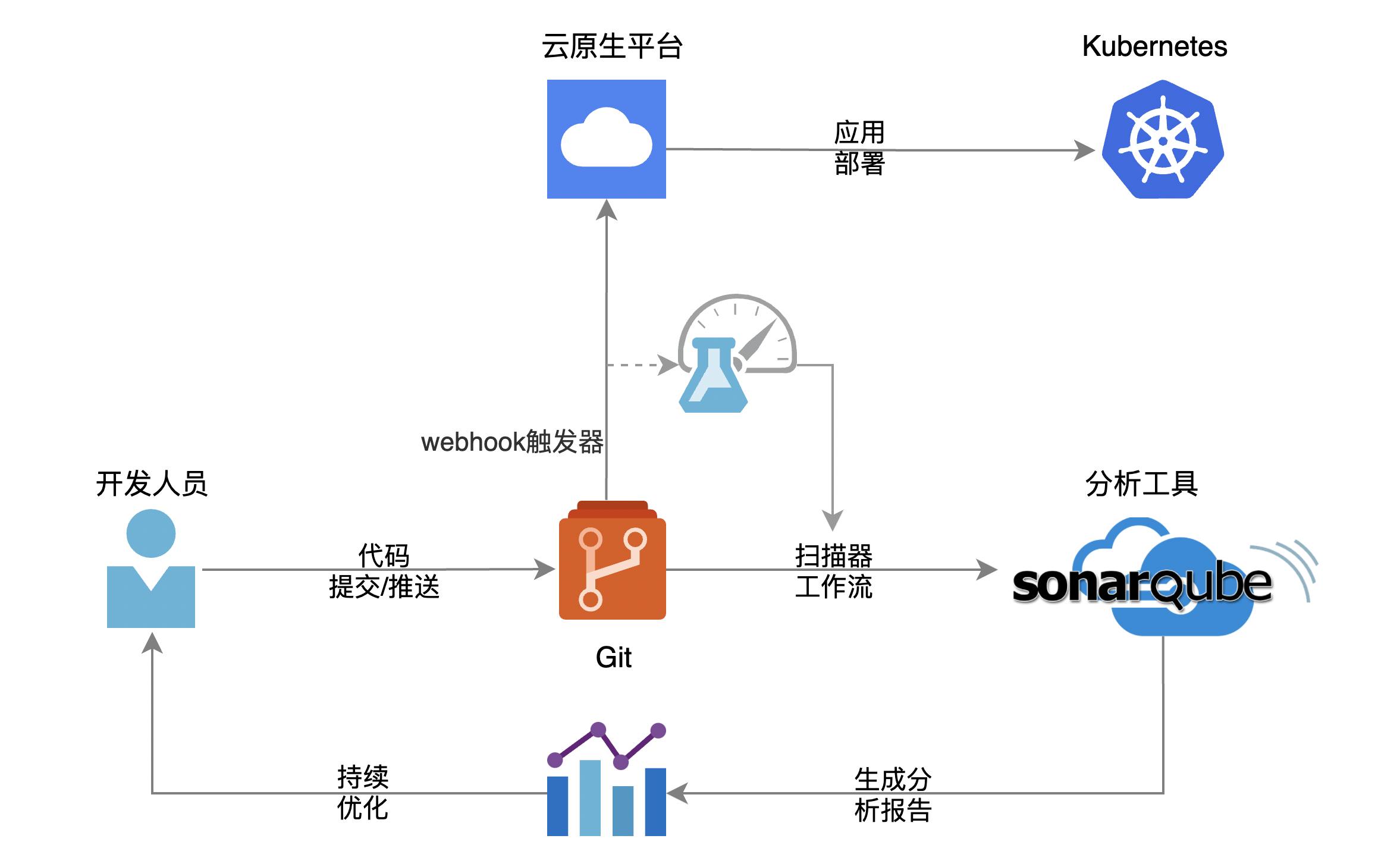
这样的使用体验还有一个优点,从始至终都不需要开发人员去编写格式严苛的 Kubernetes 声明式配置文件。这对开发人员而言无疑是一个极大的利好,Kubernetes 虽好,但学习曲线非常陡峭。Kubernetes 默认通过 yaml 格式的声明式配置文件来部署业务系统,其中绝大多数的字段定义都是运维特征的体现,换句话说,绝大多数的字段定义,都不应该是开发人员关注的事情。
DevOps 工程师应该抓住开发人员使用 Kubernetes 的痛点,避免其接触复杂运维事务。云原生平台理应提供这种使用体验,让开发人员对 Kubernetes 完全无感知的情况下,完成业务系统的部署工作。换句话说,让 Kubernetes 变得对开发人员“透明”。
从这个方面来说,通过对三款开源云原生平台的体验,发现 Rancher 和 KubeSphere 虽说均可以基于图形化界面来部署自己的业务组件,然而这些图形化配置只是 yaml 声明式配置文件的 “翻译”,对于 Kubernetes 不够熟悉的用户想要顺利使用,还是有一定的门槛。Rainbond 这一点则做的非常不错,部署业务时完全感受不到 Kubernetes 的存在,对于不熟悉 Kubernetes 的用户而言非常友好。然而产品化定制的程度越高,跟随 Kubernetes 前进的脚步就越难,上游 Kubernetes 不断在推出新的功能特性,如何将新特性抽象成为用户易于理解的功能将会是个挑战。最新版本的 Rainbond 推出了 Kubernetes 属性这一功能特性,允许用户以 yaml 形式编辑 workload ,也是为打破自设的“天花板”。
降低操作基础设施的难度
既然要设计一款平台级的软件产品,那么就需要将复杂且不易被掌握的技术,抽象成为用户易于理解的功能。DevOps 工程师设计的云原生平台产品,首要任务之一,是能够降低开发人员使用基础设施的门槛。这个章节主要讨论的,是开发人员自�行管理自己业务系统的运维特征。
就拿存储这件事来说,开发人员到底关注什么呢?
围绕存储这个概念,我们可以说出一堆名词,块设备、文件系统、对象存储、本地磁盘、磁盘阵列、NFS、Ceph等等。这些名词毋庸置疑都与存储相关,也的确会被各种业务系统所使用,但我相信,绝大多数的开发人员对这些名词并不关心。
作为用户,开发人员只关心一件事情,我所负责的业务系统,指定目录中的数据需要被持久化的保存下来。
大多数情况下,业务系统涉及到的存储场景都应该是简单的。在云原生时代,我们甚至呼吁开发人员在开发业务系统的时候,应该尽量做到“无状态化”,即在业务系统中,不存在限制实例横向扩容的状态数据,至少做到不同实例之间,数据可以共享。根据这一点,DevOps 工程师们完全可以为开发人员提供一个能够适应大多数场景的默认存储类型,各个云厂商提供的 NAS 类型存储是个很好的选择。
使用复杂存储的场景更多见于业务系统所调用的各种中间件中,比如数据库需要高速稳定的块设备类型存储,再比如大数据领域的“存算分离”场景下对接对象存储等等。然而在大多数场景下,这些复杂中间件的维护并不是开发人员应该关心的事情。它们由专门的运维人员进行维护,开发人员只需要得到访问它们的地址即可。
所以在这种简单存储场景下,开发人员最好可以仅仅填写一下自己需要被持久化的目录地址,由云原生平台来实现底层存储的配置。对存储基础设施的操作,开发人员并不需要关心。
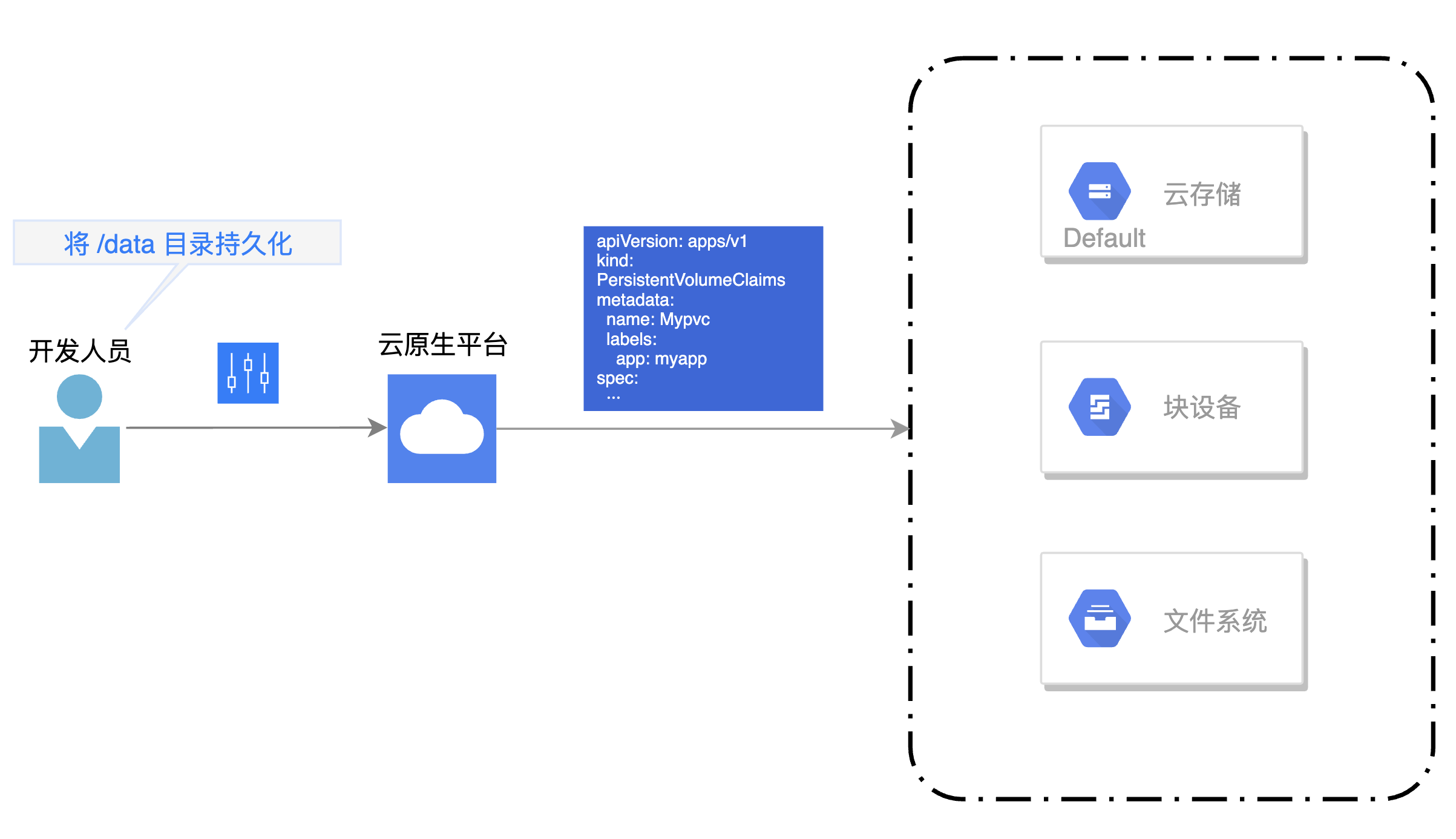
从使用体验上来说,Rancher 和 KubeSphere 可选择的存储类型很多,这是因为它们的产品生态优于 Rainbond ,比如 Rancher Lab 直接推出了轻量级的存储解决方案 Longhorn,对于各大公有云厂商提供的存储产品驱动也都有集成。 Rainbond 依然在易用性方面做的够好,实现了上文中仅关注业务系统持久化目录的使用体验。然而仅对 NFS 类型的存储支持比较完善,对于其他类型的存储支持,需要在底层基础设施中自建驱动,安装起来不如前二者方便。
易于理解的应用模型
从工作负载层面上讲,Kubernetes 只通过 Deployment、Statefulset 等抽象描述单个组件的特征,然而多数情况下,开发人员开发出的业务系统会包含若干微服务组件。那么如何对整个业务系统进行统一的管理就变成了一个问题。解决方案之一,就是通过云原生应用平台,在单个组件之上,抽象出应用这个概念。应用应该是由人为规定的一组服务组件(workload)组成,服务组件之间具有显式或隐式的关联调用关系,彼此之间有机组合成为一个整体,作为一套完整的业务系统对外提供服务。
开发人员可以将所有的服务组件视作一个整体来进行管理,而非机械的单独管理每一个服务组件,这种操作体验无疑会更简单,也便于开发人员理解。对应用的管理可以包括统一的生命周期管理、统一的安装升级卸载,灵活拼装服务组件之间的调用关系,更合理的处理业务系统的交付流程。
目前 Kubernetes 领域内较为成熟的交付工具 Helm ,其设计也暗合此类模型,一条简单的 helm install xxx 命令,即可安装起一大堆组件以及围绕这些��组件的配置。
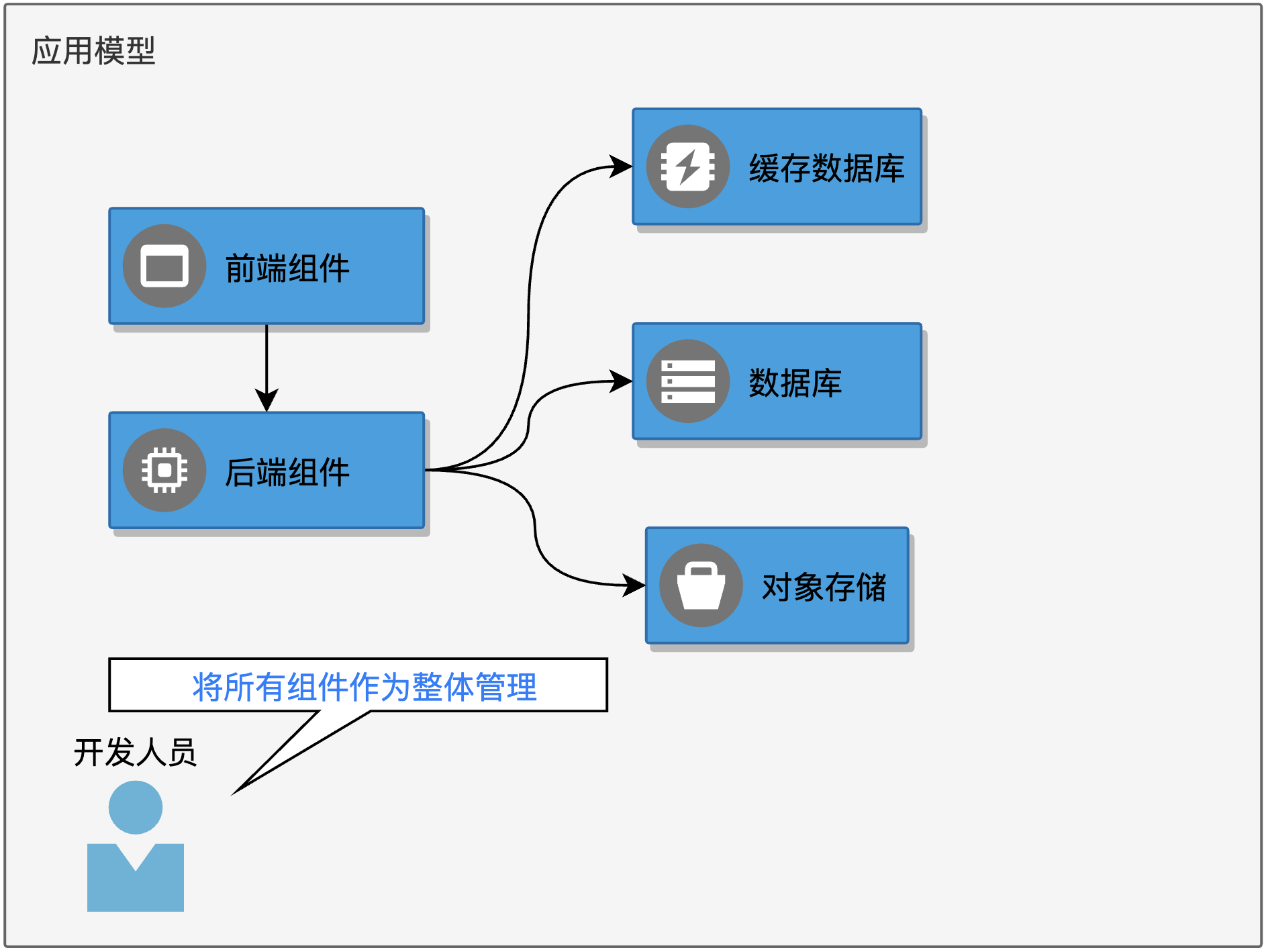
Rancher 并没有实现自己的应用模型,其应用的安装方式集成了 Helm ,并没有体现出应用管理能力。
KubeSphere 则更进一步,在项目下的应用负载中提出了应用的概念。在应用中可以通过 Helm 或自建的形式部署服务,集成了微服务治理、单个组件的版本控制、路由管理、灰度发布等能力。其对 Helm 模板的支持,使得其从理论上可以支持任何市面上已有的 Helm Chart 包的安装部署。
Rainbond 的应用概念是最完善的,除了常规的生命周期操作、整个应用级的版本控制这样的常规能力之外,还有些非常易用的自研功能,能够简化开发人员对自己应用的管理。比如基于泛解析域名机制实现的对外服务域名,点击开启对外服务,就会生成一个公网可用的域名访问自己的应用,这比一层一层的配置 Ingress 规则容易太多。又比如应用复制能力,可以批量的将整套应用复制到另一个工作空间,而不必重新手动搭一套。
应用模板是 KubeSphere 和 Rainbond 均提出的一个概念,应用模板存在的意义是可以将开发好的应用复制到不同的环境中去,是一种制备新一代制品并交付分发的技术。应用模板的基础使用体验,是可以快速方便的安装整套应用系统,最好是一键化的体验,KubeSphere 和 Rainbond 都提供了应用商店,供用户快速安装一些已经制作好的应用模板。应用模板更高层次的使用体验,则是开发人员可以无任何技术负担的开发出自己的应用模板,而不仅仅是从应用商店拉取别人制作好的应用模板。
易于掌控的微服务架构
微服务架构也是云原生平台不可缺少的一个元素。微服务架构旨在帮助开发人员建设高类聚、低耦合的现代应用系统,将以往烟囱式的业务系统架构,拆散成为一大堆彼此间更为独立,包含自身功能特点的微服务模块。容器与相关编排技术的成熟,为微服务架构的落地打下了基础。云原生应用平台,则为开发人员更简单的入手微服务框架提供了可能。
云原生平台首选的微服务框架,应该是以 Istio、Linkerd 为代表的 Service Mesh 微服务框架, 也被称为“服务网格”。相对于 Spring Cloud 、 Dubbo ,这种微服务框架提供了更高的自由度和适应性,开发人员不需要被某种开发语言或产品绑定,只需要回归网络编程即可将自己的业务系统连接成为一个整体。这里要重点提出的是微服务架构对业务代码无侵入,只有无侵入的实现,才能最大限度降低开发人员花费精力学习其他领域知识的可能性。
DevOps 工程师可以通过设计云原生平台功能来进一步优化配置微服务的使用体验,大胆设想一下,开发人员只需要在两个服务组件之间拖动一条表征微服务调用关系的线,就可以生成对应的微服务配置。这样的操作体验完全可以使注册中心、控制平面这种微服务领域中复杂的概念对开发人员屏蔽。本质上讲,维护注册中心或者控制平面也是运维人员需要关心的工作。
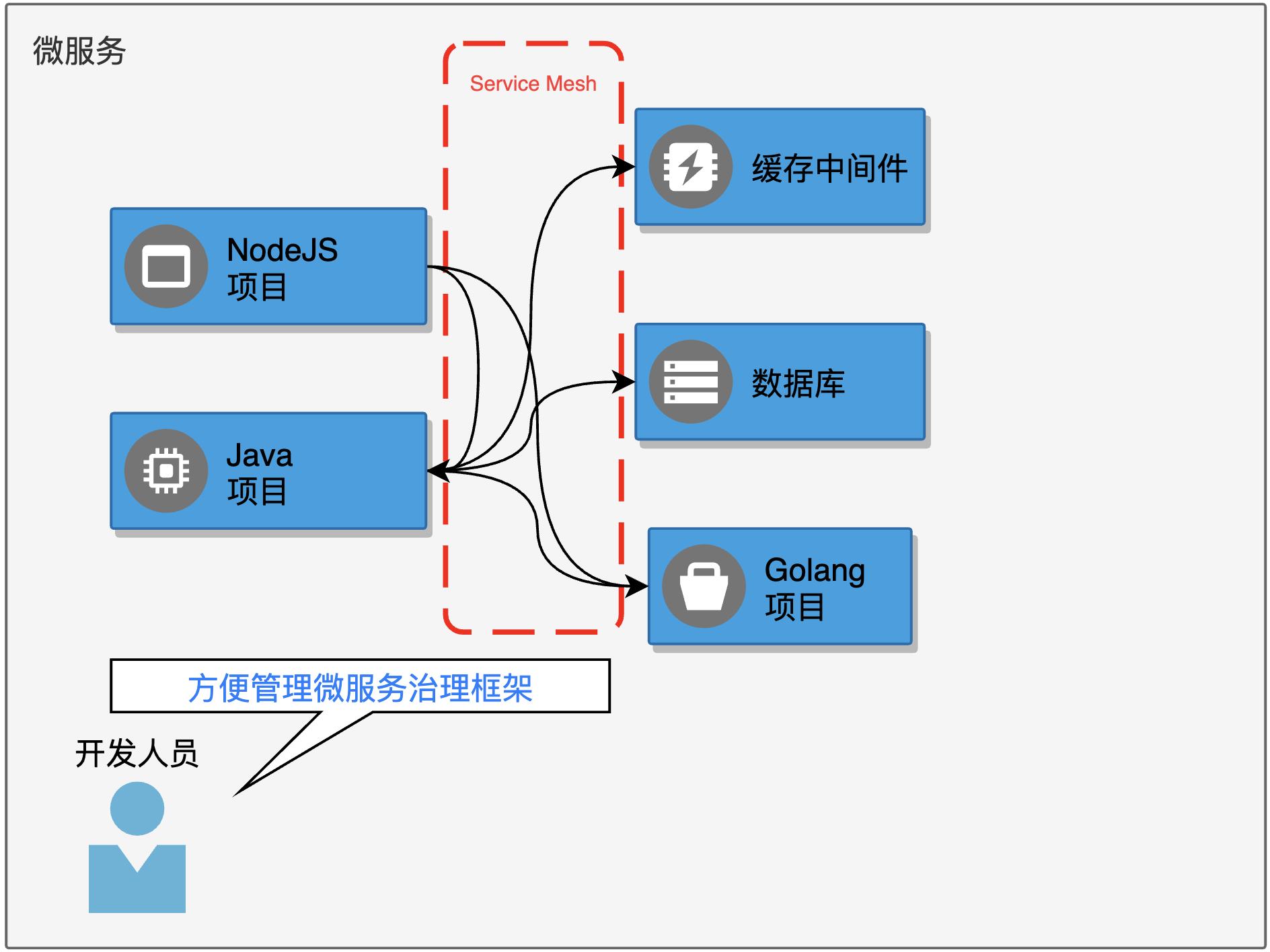
Rancher 由于其自身的定位,产品中没有集成任何微服务相关的能力,用户需要手动安装 Istio 等微服务框架, 通过复杂��的 yaml 配置,来引用微服务能力。
KubeSphere 和 Rainbond 都在应用层面默认集成了 Service Mesh 微服务框架,不同之处是前者集成了 Istio 方案,而后者的 Service Mesh 微服务框架是自研的。从使用体验上来说, KubeSphere 产品化的包装了 Istio,大幅度降低了 Istio 的使用体验,但这不意味着用户可以完全抛却 Istio 这一层的概念,应用内部的拓扑依靠事先的配置来体现。Rainbond 自研的微服务框架易用性更高一些,已经实现了拖拉拽式的微服务拼装模式,这一点还是很惊艳的。然而自己造的轮子过多,外部的其他方案有好的特性时想要快速集成接纳,就需要在微服务规范的对接层次更上层楼,毕竟 Istio、Linkerd 这些 Service Mesh 微服务框架一统江湖的情况下,其他生态的结合都会以它们为标准,而非自研框架。目前 Rainbond 也提供集成方式接纳了 Istio 治理模式,但还没有得到大量用户的使用验证。
对运维人员友好
之前的探讨,都是以开发人员为受众去考量的,但我们不应该忘记维护着底层基础设施正常工作的运维人员。任何软件的稳定运行都只是暂时的,出问题只是一个时间问题。云原生平台本身作为开发人员的基础设施,也需要被持续的维护。如何优化运维人员的管理体验,也是在云原生平台设计过程中的重点。
当今时代,Kubernetes 的使用与维护、容器化技术都已经成为了运维人员的标志性技能,对操作系统的掌控以及命令行工具的使用则是运维人员的看家本领。所以云原生平台在面向运维人员的设计中,不必要在易用性或图形化上考虑过多,更多要考虑的是可靠性、安全性、底层基础设施生态的兼容性。
Rancher 在运维层面的表现非常出众。得益于其丰富的周边生态,Rancher 在各个领域都得到了自家其他产品的原生支持。首当其冲的就是 RKE/RKE2/K3S 这几个 kubernetes 发行版,降低了不同场景下 Kubernetes 的安装难度。容器安全方面有 NeuVector 容器安全平台负责全生命周期的管理。基础设施方面有轻量级分布式块设备存储系统 Longhorn。除了丰富的生态之外,Rancher 产品界面的设计尤其符合运维人员的喜好。个人体验过程中认为 Kubectl Shell 非常惊艳,这是一个分屏式的命令行操作界面,运维人员可以一边在下半分屏 Shell 交互分页中敲命令,上半分屏中实时观察操作结果。
KubeSphere 也比较适合运维人员维护和管理。尤其是在监控报警层面,KubeSphere 制作了大量符合自身产品理念的可观测性图表,体验很不错。对于集群或节点的控制也做了图形化的设计,便于运维人员掌控。生态方面,KubeSphere 背靠青云,也在不断发展围绕自身的云原生项目,可以利用自家的驱动对接青云的云平台、云存储,以及负载均衡等基础设施。其内置的可插拔式的组件管理系统,可以快速扩展出平台级的其他能力。
Rainbond 对运维人员不太友好,甚至是一种“遗忘”了运维人员的设计理念。体验之后发现所有的运维操作依然离不开登录服务器这个前提。没有提供图形化亦或者命令行交互界面来操作集群和节点。对接多集群时,提供了图形化安装 Kubernetes 集群继而安装 Rainbond 的能力,体验还算不错。产品生态相较 Rancher 不够丰富,好在官方提供了很多文档支撑,来对接��很多其他的云原生生态产品。比如提供文档对接阿里云ACK、华为云CCE、腾讯云TKE等云基础设施的安装方式。
在用户权限管理方面,Rancher 、KubeSphere 沿用了 Kubernetes RBAC 这一套体系,Rainbond 依然有些特立独行,权限管理体系并没有完全对照原生 Kubernetes RBAC 设计,甚至在使用 Rainbond 的时候,完全没有感觉到有 RBAC 体系的存在。对接外部的身份管理系统时,KubeSphere 主推 LDAP 协议,而 Rainbond 使用了 Oauth2.0 协议的实现。
其他方面,诸如稳定性、行为审计、监控报警方面三款产品各自有实现,没什么太大的区别。
写在最后
相对于招聘文武全才的“全栈式”开发人员搞定所有的 IT 事务,我更倾向于找到不同领域的专家来搞定各自领域的问题。在运维事务的领域里,构建并维护一套功能齐备的云原生平台,能够更好的解决 IT 业务系统从底层基础设施到开发过程,最终到达生产上线的运维支持问题。这是对 DevOps 理念比较合理的一种落地方式。
文中重点提到了 Rancher 、KubeSphere、Rainbond 这三款云原生平台级产品各自不同的实现。
归纳起来,Rancher 更偏向运维人员使用,来管理企业内部的各类 Kubernetes 基础设施。开发人员想要很好的使用 Rancher ,必须具备 Kubernetes 操作能力以及容器化技术。从这个角度来说,Rancher 的定位应该位于 PaaS 与云原生平台之间。
KubeSphere 和 Rainbond 都属于以应用为中心的云原生平台产品,二者的设计思路不同之处见仁见智。 KubeSphere 以可插拔式框架纳入了云原生领域的其他项目为己所用,将这些项目的能力串联起来为最终用户提供��一站式的使用体验,然而这样的使用体验必然是有门槛的,每纳入一个项目,最终用户难免需要同时学习该项目和 KubeSphere 自身。Rainbond 的设计思路则更加的内聚,多数功能都自研。这样做的好处是功能体系高度自我契合,最终用户的使用体验非常好,功能之间衔接关联更符合人类思维,却容易自我限定,提高了纳入其他云原生生态的门槛。
DevOps 团队可以直接选择既有的云原生平台级产品使用,也可以基于开源项目二次开发。更落地的方式是选择其中多款进行混合部署,各取所长,以提到的三款产品为例,DevOps 团队完全可以选择 Rancher + KubeSphere 或 Rancher + Rainbond 的组合,它们之间并没有冲突,向下对接基础设施,管理集群的安全性与合规性是 Rancher 最擅长的事情,向上为最终开发人员提高易用的云原生平台的使用体验则交给 KubeSphere 或 Rainbond,最终的目标,是开发人员通过云原生平台的支持,从以往的运维工作之中解放出来,将精力更多的放在所开发的业务之上。