Host-based installation
When users install Rainbond from the host on the Web interface, problems encountered can be resolved based on the content of the current documentation.
Installation procedure
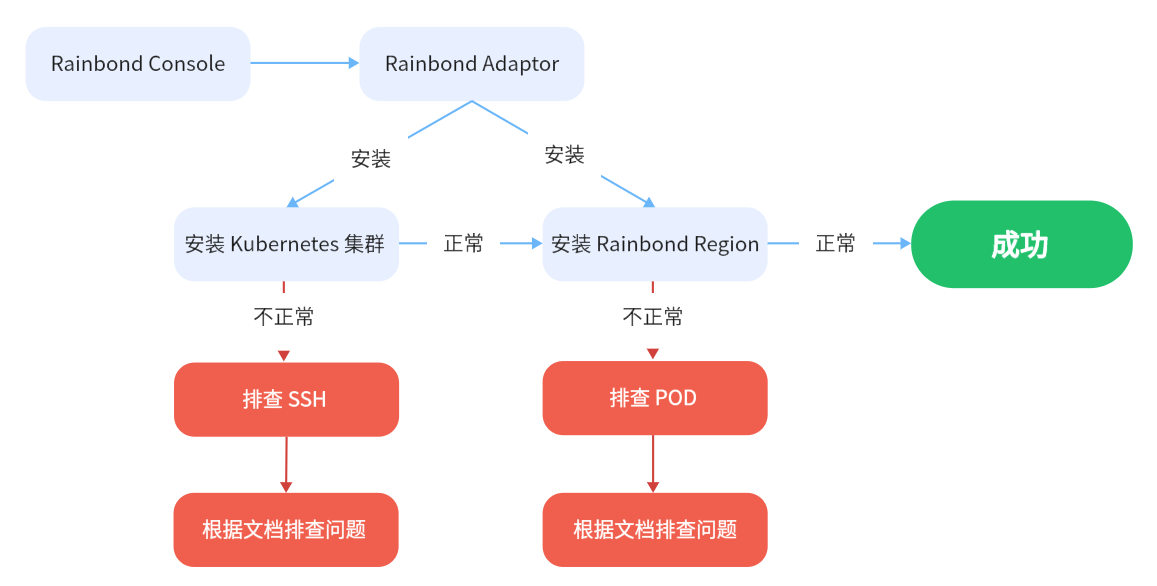
Based on the host installation process, through Rainbond console/Adaptor (https://github.com/goodrain/cloud-adaptor) and Rainbond cluster service installation Kubernetes clusters.
Process for installing a Kubernetes cluster
Based on RKE encapsulates the page operation, simplifies the installation process.
This process installs a complete set of Kubernetes clusters through the definition of a graphical interface. An error message may be displayed on the GUI during the installation. You need to manually install the Kubectl command line tool after the installation is complete to ensure that the current cluster is available.
Process for installing the Rainbond cluster
The Rainbond components are installed based on the Kubernetes cluster that has been installed in the previous step. Installation process:
- First, the Rainbond Operator is deployed, which manages the components of the Rainbond cluster.
- All subsequent Pods are created by Operator in turn.
Kubernetes installation FAQ
Cluster must have at least one etcd plane host
In this case, the node IP address or SSH port configured by you is incorrect or the port has a firewall policy, so the console cannot connect to the specified node. Reconfigure the correct node IP address and SSH port, or enable the firewall policy for the SSH port.
Another possible scenario is that the owner and owner group of the /home/docker/.ssh directory on the host node where Rainbond is installed are not docker users. Run the following command to correct the error and try again:
chown docker:docker /home/docker/.ssh
node 192.168.1.11 not found
If node 192.168.1.11 not found is displayed when you install a Kubernetes cluster on the Web page, check the kubelet logs of this node and check whether the following error occurs:
$ docker logs -f kubelet
E0329 13:07:24.125847 1061 kubelet_node_status.go:92] "Unable to register node with API server" err="Post \"https://127.0.0.1:6443/api/v1/nodes\": x509: certificate has expired or is not yet valid: current time 2023-03-29T13:07:24Z is before 2023-03-29T20:24:14Z" node="192.168.1.191"
E0329 13:07:24.141600 1061 kubelet.go:2466] "Error getting node" err="node \"192.168.1.11\" not found"
E0329 13:07:24.242506 1061 kubelet.go:2466] "Error getting node" err="node \"192.168.1.11\" not found"
If the error message is the same as the preceding, check whether the time on each node is the same. If no, synchronize the time on all nodes.
# 同步时间
ntpdate -u ntp.aliyun.com
# 硬件时间同步
hwclock -w
You are advised to restart the server after synchronizing the time.
rejected: administratively prohibited
In this case, the sshd service configuration of the host server is limited. Edit the '/etc/ssh/sshd_config' file of the host to confirm that the following configuration exists:
AllowTcpForwarding yes
After the modification, restart the sshd service:
systemctl restart sshd
Can't retrieve Docker Info: error during connect: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/info: Unable to access node
This is usually due to the SSH connection is not caused, the default re-initialization script will add the SSH key, for non-secret login, you can solve the problem by the following command:
# 进入 rainbond-allinone 容器
docker exec -it rainbond-allinone bash
# 使用 ssh 登陆节点
ssh docker@192.168.x.xs
If no secret can't log in, please check the installation of the cluster nodes /home/docker/.ssh/authorized_keys file, Verify that the key is the same as the key in the /root/.ssh/id_rsa.pub file in the rainbond-allinone container.
Failed to bring up Etcd Plane: etcd cluster is unhealthy
This error indicates that the Etcd service is unhealthy and may be caused by repeated installation. You can view Etcd logs to troubleshoot the problem:
docker logs -f etcd
Or you can choose to clear cluster
Check the health of Kubernetes
The Kubernetes cluster is not necessarily available after the GUI installation process is complete. Please determine their health status in the following ways.
Determine whether all nodes in the Kubernetes cluster are in a healthy state by using the following command
# 检查节点
kubectl get node
# 如果某个节点处于 `NotReady` 状态,通过以下命令在对应节点查询 `kubelet` 日志,根据日志输出解决节点问题
docker logs -f kubelet
Determine whether flannel and coredns in the kube-system namespace work properly by using the following command.
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-8644d6bd8c-s2888 1/1 Running 5 30d
coredns-autoscaler-74cd6f74d9-dc4vm 1/1 Running 5 30d
kube-flannel-75nfv 2/2 Running 14 30d
rke-coredns-addon-deploy-job-kk7kq 0/1 Completed 0 30d
rke-network-plugin-deploy-job-xb9bw 0/1 Completed 0 30d
If the pod corresponding to kube-flannel and coredns is found to be in other states, it needs to query the log to solve it:
# 查询 coredns 日志
kubectl logs -f coredns-8644d6bd8c-s2888 -n kube-system
# 查询 kube-flannel 日志
kubectl logs -f kube-flannel-75nfv -n kube-system -c kube-flannel
Common problems
coredns error:plugin/loop: Loop (127.0.0.1:58477 -> :53) detected for zone ".", see https://coredns.io/plugins/loop#troubleshooting.
This problem indicates that coredns is experiencing a loop resolution problem, causing it to not work properly. Pay attention to whether the nameserver defined in the /etc/resolv.conf file of each node in Kubernetes is the local loopback address of 127.0.0.1. coredns references this file content as the upstream DNS server by default. Writing the above address will cause circular resolution, which may cause the server to crash. The solution:
- Simply change /etc/resolv.conf to nameserver followed by an available dns server address (beware that this file may be maintained by some random file that overwrites your custom values).
- Directly modify coredns configmap by defining forward-114.114.114.114 instead of "/etc/resolv.conf".
flannel error:Failed to find any valid interface to use: failed to get default interface: Unable to find default route
This error means that the host node where the flannel is located does not have a default route. As a result, the flannel cannot work properly. This is common in offline environments. The solution is to add a default route to the operating system.
The kernel version is too high or too low
Operating system kernel versions below 3.10.0-514 will not be supported by the docker overlay2 storage engine.
Some kernels with versions higher than 5.16 will cause containers not to be created.
Recommended reference/upgrade the kernel version to install the kernel - lt branch of long-term support version of the kernel.
Rainbond cluster initialization Exception analysis
Prompts in the Web page
In the process of docking, you can click 'view components' to observe the installation progress, if you encounter problems, it will be prompted in the page.

Common problem
rainbond-operator error:open /run/flannel/subnet.env: no such file or directory
This problem means that flannel is not working properly. Refer to the previous section to find out how to check the corresponding log and resolve it.
Troubleshoot faults on the cluster
During the Rainbond installation process, it is also necessary to know the status of all Pods in the 'RDB-system' namespace.
After confirming that the Kubernetes cluster is healthy, you can check the status of each Pod in the Rainbond cluster.
- View the status of all Rainbond components. All Rainbond components are in the 'rbd-system' namespace
$ kubectl get pods -n rbd-system
NAME READY STATUS RESTARTS AGE
mysql-operator-7c858d698d-g6xvt 1/1 Running 0 3d2h
nfs-provisioner-0 1/1 Running 0 4d2h
rainbond-operator-0 2/2 Running 0 3d23h
rbd-api-7db9df75bc-dbjn4 1/1 Running 1 4d2h
rbd-app-ui-75c5f47d87-p5spp 1/1 Running 0 3d5h
rbd-app-ui-migrations-6crbs 0/1 Completed 0 4d2h
rbd-chaos-nrlpl 1/1 Running 0 3d22h
rbd-db-0 2/2 Running 0 4d2h
rbd-etcd-0 1/1 Running 0 4d2h
rbd-eventlog-8bd8b988-ntt6p 1/1 Running 0 4d2h
rbd-gateway-4z9x8 1/1 Running 0 4d2h
rbd-hub-5c4b478d5b-j7zrf 1/1 Running 0 4d2h
rbd-monitor-0 1/1 Running 0 4d2h
rbd-mq-57b4fc595b-ljsbf 1/1 Running 0 4d2h
rbd-node-tpxjj 1/1 Running 0 4d2h
rbd-repo-0 1/1 Running 0 4d2h
rbd-webcli-5755745bbb-kmg5t 1/1 Running 0 4d2h
rbd-worker-68c6c97ddb-p68tx 1/1 Running 3 4d2h
- If the Pod status is not Running, you need to view Pod logs to locate the problem.
example:
Viewing component logs
kubectl logs -f <pod name> -n rbd-system
Common Pod abnormal status
Pending
This status usually indicates that the Pod has not yet been scheduled on a Node. You can view the current Pod event by using the following command to determine why it has not been scheduled.
kubectl describe pod <pod name> -n rbd-system
View the Events field and analyze the cause.
- Waiting or ContainerCreating
This state usually indicates that the Pod is in a waiting or creation state, and if it is in this state for a long time, view the events of the current Pod by using the following command.
kubectl describe pod <pod name> -n rbd-system
View the Events field and analyze the cause.
imagePullBackOff
This status usually indicates that the mirror failed to be pulled. Run the following command to check which mirror failed to be pulled, and then check whether the mirror exists locally.
kubectl describe pod <pod name> -n rbd-system
View the Events field to view the image name.
Check whether the image exists locally
docker images | grep <image name>
CrashLoopBackOff
The CrashLoopBackOff status indicates that the container has been started but exits abnormally. Generally, the problem is the application itself, so you should check the container log first.
kubectl logs --previous <pod name> -n rbd-system
Evicted
In general, it is due to insufficient system memory or disk resources. df -Th can view the resource usage of the docker data directory. If the percentage is greater than 85%, it is necessary to clean up the resources in time, especially some large files and docker images.
To clear a pod whose status is Evicted, use the following command:
kubectl get pods | grep Evicted | awk '{print $1}' | xargs kubectl delete pod
FailedMount
If the volume fails to be mounted, check whether the specified file system clients are installed on all host nodes. For example, Rainbond installs nfs as cluster shared storage by default, and you might see the following error in Events: Unable to attach or mount volumes: unmount volmes=[grdata access region-api-ssl rainbond-operator-token-xxxx]: timed out waiting for the condition. This is usually because the host does not have an nfs client package such as NFs-client or NFS-common installed.