监控大屏
大屏监控是资源数据分析工具,主用于对集群和平台的各项资源进行实时监控,将数据进行可视化展示。主要包含了集群信息、节点信息以及平台信息等内容,帮助我们更高效的发现问题,维护集群和平台的稳定性。
主要功能
大屏监控应用主要分为资源监控和应用监控两大模块,点击头部标题可进行切换。
在 Kubernetes 集群中进行资源监控是非常重要的,因为它可以帮助运维人员了解整个集群和各个节点或容器的资源使用情况。关注集群的 CPU、内存等资源使用情况可以更好地管理和优化集群的性能、可用性、效率和成本,提高系统的稳定性和可维护性。
对于应用监控,可以更好了解每个应用的资源使用情况,对于出现异常的服务,快速定位运行在集群中的哪个节点,以及平台中的团队和应用,方便开发人员更好的管理服务。
资源监控
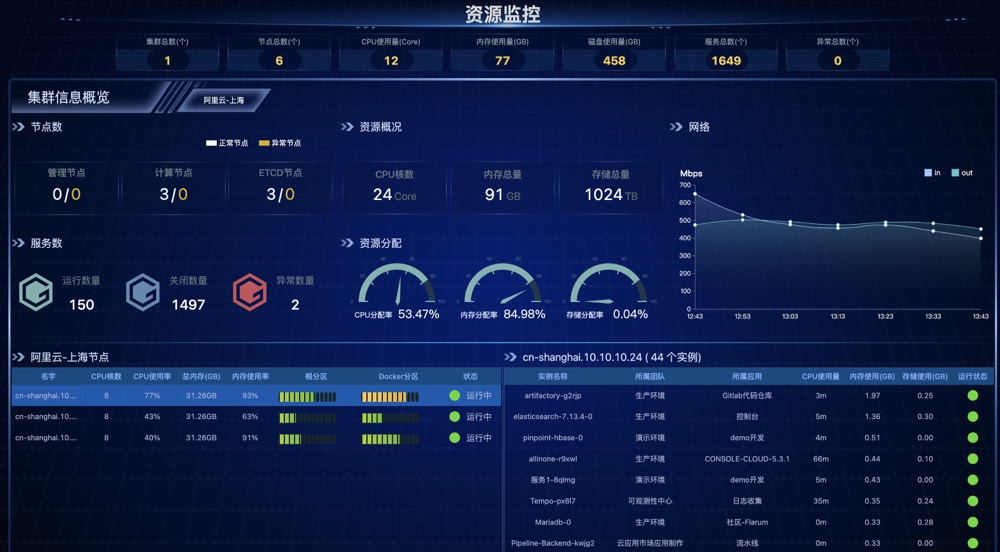
集群资源使用
- 提高系统性能和稳定性:如果 Kubernetes 集群中的节点或容器资源占用过高,可能会导致系统性能下降或容器崩溃。通过监控资源使用情况,可以及时发现这些瓶颈,并采取措施避免因资源不足而导致的系统崩溃和故障。
- 优化资源调度和分配:Kubernetes 通过资源管理器来调度和分配资源,确保每个容器或节点都有足够的资源可用。通过监控 CPU、内存等资源使用情况,可以更好地了解每个容器或节点的资源需求,从而更有效地进行资源调度和分配。
- 避免资源浪费:过多的资源分配可能导致资源浪费,影响系统的效率和可扩展性。通过监控资源使用情况,可以及时发现哪些节点或容器正在浪费资源,并采取措施来优化它们的资源使用情况,避免不必要的资源浪费。
- 节省成本:对资源的监控可以帮助您更好地了解系统的资源使用情况,从而根据实际需求进行资源规划和扩容。这可以帮助您避免不必要的资源浪��费,同时节省成本。
节点状态
- 在Kubernetes中,有多种类型的节点可用,每个节点类型都有其特定的用途和功能。对接不同的集群,节点类型和数量会不相同,这里我们主要关心各节点的状态是否正常。
网络
- Kubernetes 集群中的容器和服务经常需要通过网络进行通信,网络带宽是影响通信速度和延迟的关键因素。通过监控网络带宽值,可以及时发现网络瓶颈和网络性能问题,并采取措施优化网络性能,确保网络稳定和快速响应。
节点资源使用
- 故障检测和排除:每个节点在 Kubernetes 集群中扮演着非常重要的角色,如果某个节点发生故障,可能会影响整个集群的稳定性和可用性。通过监控每个节点的状态,可以及时发现故障节点,并采取措施修复或替换节点,避免故障扩散和影响集群的稳定性。
- 资源规划和管理:每个节点在 Kubernetes 集群中承担着一定的资源负责,包括 CPU、内存、存储和状态等。通过监控每个节点的资源使用情况,可以更好地了解节点的负载情况,从而优化资源规划和管理,提高资源利用率和效率。
- 故障预测和优化:通过监控每个节点的状态和资源使用情况,可以更好地了解节点的健康状况和性能表现,��从而预测可能的故障和性能瓶颈,及时采取措施避免故障的发生,或优化节点的性能表现,提高系统的可靠性和性能。
运行实例
- 观察运行在每个节点上的实例,可以了解该实例自身的资源使用情况,所在节点的状况,可以快速定位到平台对应的团队和应用,进行故障分析和性能调整,维护运行在平台上业务的稳定性。
应用监控
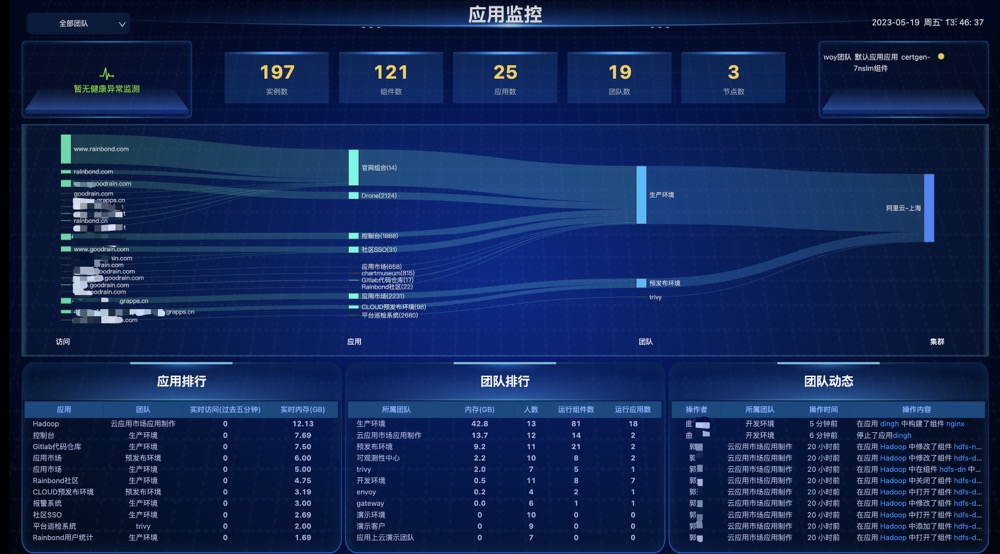
流量分布图
- 识别热点:服务流量分布图可以帮助我们识别服务的热点,即最常被使用的部分。这些热点可能会导致性能问题,需要特别关注。
- 优化性能:通过分析服务流量分布图,我们可以找到服务的瓶颈,了解服务的瓶颈位置,进而针对性地进行优化,提高服务的性能。
- 规划容量:服务流量分布图可以帮助我们了解服务的使用情况,帮助我们规划容量,确保服务能够承受未来的负载压力。
应用资源排序
- 可以很容易地发现哪些服务消耗了过多的内存资源,以便我们及时发现和解决内存占用过高等问题。
- 我们可以更好地了解集群中每个服务的资源使用情况,以便我们在资源分配时进行更优化的决策,从而更好地利用集群资源。
- 可以及时发现哪些服务的内存占用超过了其限制,以便我们可以采取相应措施,避免服务因内存不足而崩溃。
团队资源排序
- 可以更好了解团队的内存使用,是否达到或者超出团队的资源限制。
- 观察团队的人数和运行的应用数、组件数哪些比较高,要合理分配资源的使用。
使用手册
访问大屏监控,能实时的展示集群和平台的信息,可以根据指标分析其性能、健康以及资源使用情况。
资源监控
-
页面顶部展示了集群总数以及所有集群资源使用量汇总,其中服务总数为平台中部署的组件总个数,而异常总数统计的是集群中常见的问题数量,比如内存磁盘不足、网络不可用、进程数过多等,重点要关注异常总数。
-
集群信息概览则展示某个集群的详情,主要有节点数、服务数、资源概况、资源分配、网络、节点信息、实例信息等内容。
- 节点数重点关注异常节点的数量。
- 服务数为平台中部署的组件数量,按照运行、关闭和异常三种状态区分,异常组件一般是由于部署服务出现问题或配置出现问题,如果数量突然变多,那么很可能是因为集群问题导致的,要重点关注异常数量。
- 资源概况展示该集群的 CPU、内存、存储总量。
- 资源分配展示 CPU、内存、存储的分配率,CPU 和内存占比过高会影响集群的性能和稳定性,部署在集群中的应用程序性能下降,也可能导致节点崩溃;
- 网络折线图反映集群网络带宽,根据工作负载和集群的大小而变化,需要注意的是网络带宽并不是影响集群性能的唯一因素。延迟、数据包丢失和网络拥塞等其他因素也会影响集群的性能。如果需要优化集群的网络性能,您应该考虑使用高性能的网络基础设施,例如专用的网络接口卡(NIC)或带有高速背板的网络交换机。此外,您应该配置您的网络,以便对节点之间的流量进行优先级排序,并尽量减少网络拥塞。
- 下方节点部分展示该集群中所有的节点信息,包括每个节点的资源使用情况,如 CPU 核数,CPU 使用率,总内存,内存使用率,根分区、docker 分区、状态;其中资源使用率过高会影响当前节点的性能和稳定性,需要注意关闭和释放不必要的资源。
- 实例部分展示运行在某个节点下的实例数,包括每个实例的资源使用情况,以及该实例在平台上所属的团队和应用。
应用监控
-
页面顶部汇总了平台资源总数,如实例数、组件数、应用数、团队数和节点数。
-
流量结构分布图主要用于展示访问流量的流动与分布,具体链路为
域名 -> 应用 -> 团队 -> 集群。 -
左上角可选择指定团队查看应用信息,默认展示全部团队:
- 应用排行:统计平台中应用的访问量以及实时内存;
- 团队排行:统计平台中的各个团队人数和应用组件数;
- 团队动态:展示平台中的操作日志。