基于主机安装
当用户在 Web 界面中从主机开始安装 Rainbond 时,所遭遇的问题可以依靠当前文档的内容进行排查与解决。
安装流程
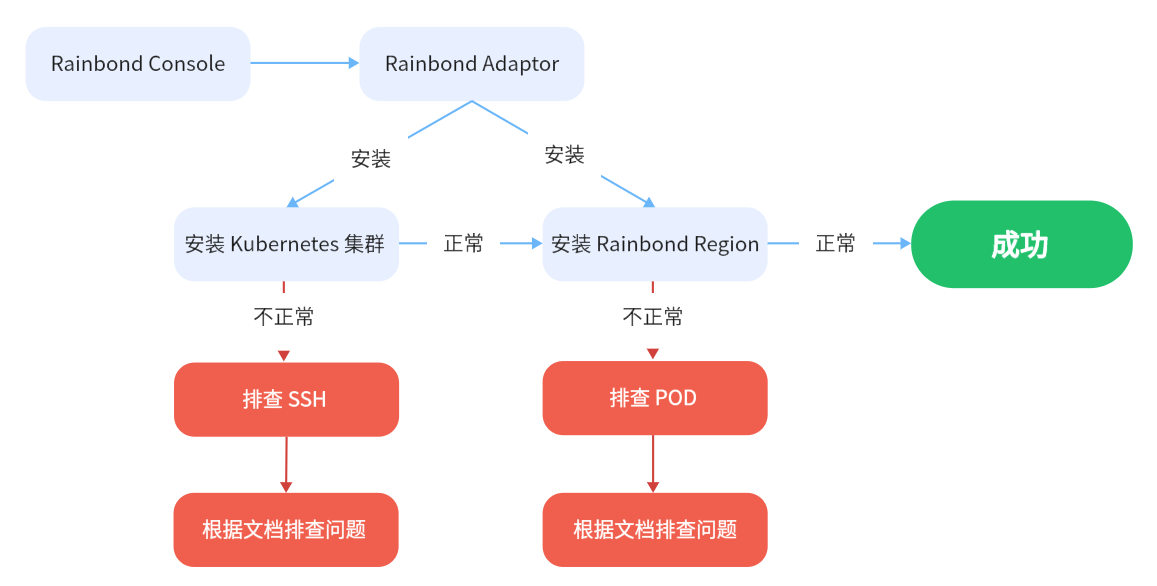
基于主机安装的流程中,通过 Rainbond 控制台的 Adaptor 服务安装 Kubernetes 集群和 Rainbond 集群。
安装 Kubernetes 集群流程
-
基于 RKE 封装了页面操作,简化了安装过程。
-
该过程通过图形化界面的定义,安装了一套完整的 Kubernetes 集群。在安装过程中可能触发图形化界面的报错提示,也需要在安装完成后,手动安装 Kubectl命令行工具,确认当前集群可用。
安装 Rainbond 集群流程
该过程基于上个步骤已经安装好的 Kubernetes 集群继续安装 Rainbond 各组件。安装的过程:
- 首先会部署 Rainbond Operator,该组件负责管理 Rainbond 集群的各个组件。
- 后面所有 POD 都会通过 Operator 依次创建。
Kubernetes 安装常见问题
Cluster must have at least one etcd plane host
这种情况一般是你配置的节点 IP 地址或 SSH 端口不正确或端口有防火墙策略,导致控制台无法连接指定的节点。重新配置正确的节点 IP 地址和 SSH 端口,或开启 SSH 端口的防火墙策略。
另一种可能的情况,是安装 Rainbond 所使用的宿主机节点中, 目录 /home/docker/.ssh 的属主和属组不是 docker 用户,执行以下命令改正后重试:
chown docker:docker /home/docker/.ssh
如果都无�法解决此问题,您可以重新生成密钥对。 SSH密钥对由私钥(私有密钥)和公钥组成。使用私钥进行身份验证,并将公钥放置在服务器上以授权访问。要生成SSH密钥对,请在终端中运行以下命令:
ssh-keygen -t rsa
复制公钥到服务器。公钥文件的默认位置是~/.ssh/id_rsa.pub。你可以使用以下命令将公钥复制到目标服务器上:
# 将下方 ip 替换成您的真实 IP
ssh-copy-id docker@1.1.1.1
验证免密登录是否成功。现在,你应该能够通过以下命令直接登录到服务器,而无需输入密码
ssh docker@1.1.1.1
node 192.168.1.11 not found
通过 Web 页面安装 Kubernetes 集群时出现 node 192.168.1.11 not found,查看该节点的 kubelet 日志,确认是否存在以下报错:
$ docker logs -f kubelet
E0329 13:07:24.125847 1061 kubelet_node_status.go:92] "Unable to register node with API server" err="Post \"https://127.0.0.1:6443/api/v1/nodes\": x509: certificate has expired or is not yet valid: current time 2023-03-29T13:07:24Z is before 2023-03-29T20:24:14Z" node="192.168.1.191"
E0329 13:07:24.141600 1061 kubelet.go:2466] "Error getting node" err="node \"192.168.1.11\" not found"
E0329 13:07:24.242506 1061 kubelet.go:2466] "Error getting node" err="node \"192.168.1.11\" not found"
如果报错与上述一致,请检查每个节点之间的时间是否一致,如果不一致,请将所有节点的时间同步。
# 同步时间
ntpdate -u ntp.aliyun.com
# 硬件时间同步
hwclock -w
建议同步时间后重启服务器再继续安装。
rejected: administratively prohibited
这种情况说明宿主机服务器的 sshd 服务配置有限制,编辑所欧宿主机的 /etc/ssh/sshd_config 文件,确定存在以下配置:
AllowTcpForwarding yes
修改完成后重启 sshd 服务:
systemctl restart sshd
Can't retrieve Docker Info: error during connect: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/info: Unable to access node
这种情况一般也是由于 SSH 连接不上导致的,默认再初始化脚本中会添加 SSH 密钥,用于免密登陆,你可以通过以下命令排查问题:
# 进入 rainbond-allinone 容器
docker exec -it rainbond-allinone bash
# 使用 ssh 登陆节点
ssh docker@192.168.x.xs
如果免密无法登陆,请查看所安装集群节点上的 /home/docker/.ssh/authorized_keys 文件,确认其中的密钥是否与 rainbond-allinone 容器中的 /root/.ssh/id_rsa.pub 文件中的密钥一致。
Failed to bring up Etcd Plane: etcd cluster is unhealthy
该报错代表 Etcd 服务不健康,可能是重复安装导致的,可以查看 Etcd 日志排查解决问题:
docker logs -f etcd
或者可以选择重新 清理集群
确认 Kubernetes 健康
Kubernetes 集群在图形化界面的安装过程完成后,未必代表该集群一定可用。请通过以下方法确定其健康情况。
通过以下命令,确定 Kubernetes 集群中的节点是否都处于健康状态
# 检查节点
kubectl get node
# 如果某个节点处于 `NotReady` 状态,通过以下命令在对应节点查询 `kubelet` 日志,根据日志输出解决节点问题
docker logs -f kubelet
通过以下命令确定 kube-system 命名空间中的 flannel 以及 coredns 工作是否正常。
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-8644d6bd8c-s2888 1/1 Running 5 30d
coredns-autoscaler-74cd6f74d9-dc4vm 1/1 Running 5 30d
kube-flannel-75nfv 2/2 Running 14 30d
rke-coredns-addon-deploy-job-kk7kq 0/1 Completed 0 30d
rke-network-plugin-deploy-job-xb9bw 0/1 Completed 0 30d
如果发现 kube-flannel 以及 coredns对应的 pod 处于其他状态,则需要查询日志加以解决:
# 查询 coredns 日志
kubectl logs -f coredns-8644d6bd8c-s2888 -n kube-system
# 查询 kube-flannel 日志
kubectl logs -f kube-flannel-75nfv -n kube-system -c kube-flannel
常见的问题
coredns报错:plugin/loop: Loop (127.0.0.1:58477 -> :53) detected for zone ".", see https://coredns.io/plugins/loop#troubleshooting.
该问题说明 coredns 遭遇了循环解析问题,导致其无法正常工作。关注下 Kubernetes 中的各节点 /etc/resolv.conf 文件中定义的 nameserver 是否是 127.0.0.1 这种本地回环地址,coredns 默认引用这个文件内容作为上游 DNS 服务器,写上述地址的话,会引起循环解析,这可能导致服务器崩溃。解决的方案:
- 直接修改 /etc/resolv.conf ,令其 nameserver 后接一个可用的 dns 服务器地址(当心这个文件可能会被某些莫名其妙的文件维护,重写你自定义的值)
- 直接修改 coredns 的 configmap,定义 forward . 114.114.114.114 来替换 "/etc/resolv.conf" 。
flannel 报错:Failed to find any valid interface to use: failed to get default interface: Unable to find default route
该报错意味着 flannel 所在的主机节点没有默认路由,导致 flannel 无法正常工作。这种情况常见于离线环境。解��决的方式是为操作系统添加默认路由。
内核版本过高或过低
操作系统内核版本低于 3.10.0-514 将导致无法受到 docker overlay2 存储引擎的支持。
版本高于 5.16 的某些内核会导致容器无法被创建。
推荐参考 升级内核版本 安装 kernel-lt 分支的长期支持版内核。
Rainbond 集群初始化异常情况分析
Web 页面中的提示
在对接的过程中,可以点击 查看组件 观察安装进度,如遭遇问题,会在页面中有所提示。

常见问题
rainbond-operator 报错:open /run/flannel/subnet.env: no such file or directory
该问题意味着 flannel 未能正常工作,参考上一章节了解如何排查对应日志并加以解决。
集群端问题排查
在安装 Rainbond 的过程中,了解 rbd-system 命名空间下所有 pod 的状态也是很有必要的。
在确认 Kubernetes 集群状态健康之后,可以开始排查 Rainbond 集群各 Pod 的状态。
- 查看 Rainbond 所有组件状态,Rainbond的所有组件都位于
rbd-system名称空间下
$ kubectl get pods -n rbd-system
NAME READY STATUS RESTARTS AGE
mysql-operator-7c858d698d-g6xvt 1/1 Running 0 3d2h
nfs-provisioner-0 1/1 Running 0 4d2h
rainbond-operator-0 2/2 Running 0 3d23h
rbd-api-7db9df75bc-dbjn4 1/1 Running 1 4d2h
rbd-app-ui-75c5f47d87-p5spp 1/1 Running 0 3d5h
rbd-app-ui-migrations-6crbs 0/1 Completed 0 4d2h
rbd-chaos-nrlpl 1/1 Running 0 3d22h
rbd-db-0 2/2 Running 0 4d2h
rbd-etcd-0 1/1 Running 0 4d2h
rbd-eventlog-8bd8b988-ntt6p 1/1 Running 0 4d2h
rbd-gateway-4z9x8 1/1 Running 0 4d2h
rbd-hub-5c4b478d5b-j7zrf 1/1 Running 0 4d2h
rbd-monitor-0 1/1 Running 0 4d2h
rbd-mq-57b4fc595b-ljsbf 1/1 Running 0 4d2h
rbd-node-tpxjj 1/1 Running 0 4d2h
rbd-repo-0 1/1 Running 0 4d2h
rbd-webcli-5755745bbb-kmg5t 1/1 Running 0 4d2h
rbd-worker-68c6c97ddb-p68tx 1/1 Running 3 4d2h
- 如果有 Pod 状态是非 Running 状态,则需要查看 Pod 日志,通过 Pod 日志基本可以定位到问题本身。
例:
查看组件日志
kubectl logs -f <pod name> -n rbd-system
常见 Pod 异常状态
Pending
这个状态通常表示 Pod 还没有调度到某个 Node 上面,可以通过以下命令查看到当前 Pod 事件,进而判断为什么没有调度。
kubectl describe pod <pod name> -n rbd-system
查看 Events 字段内容,分析原因。
- Waiting 或 ContainerCreating
这个状态通常表示 Pod 处于等待状态或创建状态,如果长时间处于这种状态,通过以下命令查看当前 Pod 的事件。
kubectl describe pod <pod name> -n rbd-system
查看 Events 字段内容,分析原因。
imagePullBackOff
这个状态通常表示镜像拉取失败了,使用以下命令查看是什么镜像拉取失败了,然后在本地查看是否有该镜像。
kubectl describe pod <pod name> -n rbd-system
查看 Events 字段内容,查看镜像名字。
在本地查看镜像是否存在
docker images | grep <image name>
CrashLoopBackOff
CrashLoopBackOff 状态说明容器曾经启动了,但又异常退出了;一般情况下都是应用本身的问题,此时应该先查看一下容器的日志。
kubectl logs --previous <pod name> -n rbd-system
Evicted
驱逐状态,多见于资源不足时导致的 Pod 被驱逐,一般情况下是由于系统内存或磁盘资源不足,可 df -Th 查看 docker数据目录 的资源使用情况,如果百分比大于85%,就要及时清理下资源,尤其是一些大文件、docker镜像。
使用如下命令可以清除状态为Evicted的pod:
kubectl get pods | grep Evicted | awk '{print $1}' | xargs kubectl delete pod
FailedMount
挂载卷失败,需要关注所有的宿主机节点是否安装了指定的文件系统客户端。例如在默认情况下,Rainbond 会自行安装 nfs 作为集群共享存储,可能会在 Events 中见到如下报错:Unable to attach or mount volumes: unmount volmes=[grdata access region-api-ssl rainbond-operator-token-xxxx]: timed out waiting for the condition。这通常是因为宿主机没有安装 nfs-client 或 nfs-common 等 nfs 客户端软件包。